3.2. Перебор строк выборки в потоковом режиме (datastream)¶
Для работы с большими списками введён режим потокового перебора строк выборки, который позволяет экономить память сервера.
С его помощью можно перебирать строки табличного и древовидного представления, а также списка с группировкой.
В данном режиме строки отдаются в том же порядке, что и при использовании CoreSelection#next(),
но, в определённый момент времени, пройденные строки выгружаются из памяти.
3.2.1. Использование¶
3.2.1.1. Навигация¶
1. Для входа в потоковый режим необходимо воспользоваться методом CoreSelection#openDataStream(),
который откроет датастрим и вернёт его экземпляр
Note
Рекомендуется использовать интерфейс CoreDataStream в блоках try-with-resources или Using,
потому что он расширяет java.lang.AutoCloseable
Для перебора строк используется метод
CoreDataStream#nextToken(), который вернёт один из следующихтокенов:BOF, первый токен после открытия датастрима
EOF, токен окончания датастрима, идущий после полного перебора строк датастора
ROW, токен строки
GROUP, токен строки группировки
RIGHT, токен сдвига вправо, т.е. переход на один уровень вложенности ниже в иерархии дерева
LEFT, токен сдвига влево, т.е. переход на один уровень вложенности выше в иерархии дерева
Note
Токены LEFT и RIGHT предназначены для возможности отражения структуры древовидного списка без запросов информации о предках/потомках узлов
Для проверки наличия следующего токена используется метод
CoreDataStream#hasNextToken()
Attention
Если вы не использовали датастрим в рамках блоков try-with-resources или Using, то необходимо закрывать его самостоятельно с помощью CoreDataStream#close()
Пример 1.
Для простого списка из трёх строк вернётся следующая последовательность токенов: BOF, ROW, ROW, ROW, EOF.
Пример 2.
Для списка с группировкой со следующего изображения
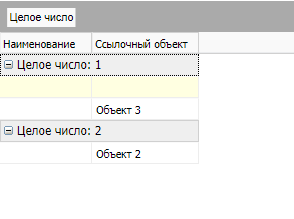
вернётся последовательность токенов: BOF, GROUP, RIGHT, ROW, ROW, LEFT, GROUP, RIGHT, ROW, EOF.
Пример 3.
Для древовидного списка со следующего изображения
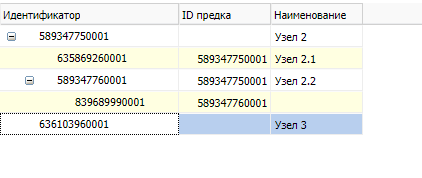
вернётся последовательность токенов: BOF, ROW, RIGHT, ROW, ROW, RIGHT, ROW, LEFT, LEFT, ROW, EOF.
3.2.1.2. Запрос данных¶
Если текущим токеном является ROW, то для получения значения из колонки для текущей строки необходимо использовать один из следующих методов:
CoreDataStream#getCellValue(String), который вернёт значение колонки с переданным именемNote
Результат вызова данного метода аналогичен результату вызова
CoreSelectionShared#getVar(String)CoreDataStream#getCellValue(int), который вернёт значение колонки по переданному индексу.Индексы соответствуют порядку атрибутов, указанному в операции GetSqlText
Если текущим токеном является GROUP, то с помощью вызова:
CoreDataStream#getGroupFieldNameможно получить имя атрибута, по которому происходит группировкаCoreDataStream#getGroupCaptionможно получить значение, по которому сформирована группа
3.2.2. Пример использования для формирования excel-документа¶
В следующем примере используется функционал Scala версии 2.13.10 и библиотеки Apache POI для создания и наполнения excel-документа
import org.apache.poi.ss.usermodel.HorizontalAlignment
import org.apache.poi.xssf.streaming.{SXSSFSheet, SXSSFWorkbook}
import ru.bitec.app.gtk.gl.selection.{Attrs, Selection}
import ru.bitec.gtk.core.datastore.{CoreDataStream, CoreDataStreamTokenEnum}
import java.nio.file.{Path, Paths}
import java.io.FileOutputStream
import scala.util.Using
protected var workbook: SXSSFWorkbook
protected var sheet: SXSSFSheet
protected def streamExport(selection: Selection, fileName: String): Unit = {
workbook = new SXSSFWorkbook()
sheet = workbook.createSheet()
Using (selection.openDataStream) { dataStream =>
fillHeaderRow(selection.attrs())
val tempExcelFilePath = Paths.get(System.getProperty("java.io.tmpdir"), fileName)
fillWorkbook(dataStream, selection.attrs(), tempExcelFilePath)
}
}
private def fillHeaderRow(attrs: Attrs): Unit = {
val headerCellStyle = workbook.createCellStyle
val headerFont = workbook.createFont
headerFont.setBold(true)
headerCellStyle.setFont(headerFont)
headerCellStyle.setAlignment(HorizontalAlignment.CENTER)
val headerRow = sheet.createRow(0)
for ((attr, colIndex) <- attrs.toList.zipWithIndex) {
val cell = headerRow.createCell(colIndex)
cell.setCellStyle(headerCellStyle)
cell.setCellValue(attr.caption)
}
}
private def fillWorkbook(dataStream: CoreDataStream, attrs: Attrs, filePath: Path): Unit = {
var rowNum = 1
var currentDepth = 0
while (dataStream.hasNextToken) {
val token = dataStream.nextToken()
token match {
case CoreDataStreamTokenEnum.Right => currentDepth += 1
case CoreDataStreamTokenEnum.Left => currentDepth -= 1
case CoreDataStreamTokenEnum.Row =>
fillSheetRow(dataStream, attrs, rowNum, currentDepth)
rowNum += 1
case CoreDataStreamTokenEnum.Eof =>
Using (new FileOutputStream(filePath.toString)) { out =>
workbook.write(out)
}
workbook.dispose()
}
}
}
private def fillSheetRow(dataStream: CoreDataStream, attrs: Attrs, rowNum: Int, rowDepth: Int): Unit = {
val row = sheet.createRow(rowNum)
for ((attr, colIndex) <- attrs.toList.zipWithIndex) {
val cell = row.createCell(colIndex)
cell.setCellValue(dataStream.getCellValue(attr.name).toString)
}
}